Experiencias desarrollando clasificador binario
 |
 |
Breve introducción:
Tuve que desarrollar un proyecto de redes neuronales convolucionales y busque proyectos en los que me pudiese basar. Después de una busqueda no tan profunda, encontre un proyecto que se me hizo interesante y pense que sería simple. El proyecto es un clasificador binario de imagenes de anime, indicando si la imagen es o no anime el proyecto donde me base. Como es únicamente un clasificador binario supuse que no habría mucha dificultad en entenderlo y me serviría como experiencia para hacer el tipo de red convolucionar clásico.
Proyecto original:
Como mencione, el proyecto en el que me basé es un clasificador binario de imagenes y este está en una página web, con un diseño muy simple, donde puedes subir una imagen o un url de una imagen y clasifica si es o no anime. También parece estar bien ordenado en carpetas: scraper en la cual obtiene las imagenes con las que entrnó su red; cleaning donde limpia y prepara las imagenes para ser usadas en el entrenamiento; training en donde define el modelo de su red y la entrena; models en donde guarda el modelo que su red utiliza; deploy en el que prepara su modelo como una función lambda de AWS (link correspondiente); website en donde guarda el codigo pertiente de su página web y por último test donde prueba su red.
Algo que cabe mencionar es que el proyecto original entrena su modelo usando AWS, el servicio de nube de Amazon, cosa que por su precio yo no me puedo permitir por lo que mucho código, así como lo tiene, no lo puedo simplemente copiar y pegar y esperar que funcione. Tengo que entenderlo y traducirlo para poder usarlo.
Cambios objetivo:
Los objetivos que originalmente me plantee fueron:
- Encontrar datos de entrenamiento por mi mismo para mis modelos
- Reusar modelos ya entrenados para disminuir el esfuerzo computacional que mi red tendrá que aplicar.
- Comparar los resultados obtenidos con los de la red del proyecto original.
- Crear una aplicación web similar a la del proyecto original pero en heroku.
En la conlusión diré cuales objetivos logré y cuales no.
Problemas encontrados
Basandome en un proyecto ya hecho y siendo solo un clasificador binario, pense que sería un trabajo sencillo pero me encontre con varios problemas.
Un pequeño aviso. Creo que en lo siguiente empezaré a hablar principalmente de problemas que me encontré con el proyecto original pero no creo que la mayoría se deban a que el autor original hizo las cosas especialmente mal sino que la mayoría se deben a mis propias limitaciones y falta de conocimiento en el tema.
-
Que herramientas usar para entrenar la red. Como el proyecto donde me basé usaba keras con tensorflow de backend, decidí usar lo mismo. El problema es que para poder usar tensorflow con GPU necesité:
-
Un GPU (obviamente)
-
Instalar los drivers de cuda y cudnn. Pero oficialmente para conseguir los drivers de cudnn es necesario registrarse como desarrollador en la página de nvidia. Para evitar esto tuve que investigar hasta encontrar con el driver por otro lado. Encontré una versión más antigua pero funcional del driver en un post de medium.
-
Para instalar keras use anaconda creando un ambiente virtual. Pero al instalar el paquete de tensorflow con soporte para gpu, tensorflow-gpu, no parecía funcionar. Después de perder tiempo revisando cual era el problema e investigando soluciones encontre que bajando la version de tensorflow-gpu a la 1.5 hacia desaparecer ese problema y por fin pude hacer que funcionara mi GPU y pudiera entrenar.
-
-
El proyecto original practicamente usaba AWS para todo por lo que habían muy pocas partes que podia copiar y pegar y que funcionaran. Este terminó siendo un gran problema que me hizo hacer mucho más trabajo de lo que esperaba y terminé reescribiendo mucho código para que yo lo pudiese usar.
-
De donde conseguir las imagenes fue un problema que me tuvo pensando por algunos días. El proyecto original usaba scrapers y conseguía imagenes de imgur, imagenet, 4chan que parece que guardaba usando AWS. En lo que estaba intentando entender como lo hizo recibí una sugerencia que no se me había ocurrido: buscar bases de datos con imagenes de anime. Eso debió haber sido lo primero que hiciera, pues en caso de haber me ahorraría tiempo entendiedo que es lo que hacen los scrapers y con suerte me proveeran de suficientes imagenes de anime.
Al buscar me encontré con una base de datos de kaggle (y necesite de una cuenta para obtener los links) y los links eran a safebooru, un sitio donde artistas y fanaticos pueden subir imagenes que creen o que les guste con numerosos tags.
Para bajar las imagenes hice un pequeño script con el que descargue imagenes durante todo un día. Gracias a que mi internet no es muy bueno solo pude descargar alrededor de 20 GB que fueron casi 40,000 imagenes de anime. entre estas imagenes se encontraban también gifs pero son trivialmente removibles.
Una vez obtenidas esas imagenes, lo siguiente fue conseguir imagenes que no fueran de anime para entrenar la red. Primero revisé los links de imagenet que el proyecto original tenía pero hay muchos rotos o que no responden, por lo que tuve que buscar en otro lado.
En mi busqueda encontre lorempicsum, un sitio con imagenes de muchas dimensiones. Especialmente importante es que tienen un método para descargar una imagen aleatoria de diferentes dimensiones. Escribí un script para descargar unas 10000 imagenes de tamaños variados para probarlo y lo deje en la noche. En la mañana lo revisé y ciertamente lo había descargado pero revisé si habían duplicados y lamentablemente si los habían. Con eso me dí cuenta que no tendría sentido seguir descargando imagenes del sitio porque para llegar al mismo número de imagenes que las de anime que descargué antes irremediablemente también descargaría más duplicados y tuve que dejarlo así. Finalmente terminé con unas 8500 imagenes de no anime.
Con las dos clases de imagenes listas, las separé en 70% de entrenamiento y 30% de validación (sin datos de prueba final).
-
Especificamente como entrenar la red. Gracias al proyecto original tengo un modelo de red neuronal que puedo utilizar pero su modo de entrenamiento no parecía aplicable para mi caso. Entonces busque ejemplos en keras de redes convolucionales de clasificación binaria y encontre dos ejemplos en los que me base principalmente para hacer el código de entrenamiento: esta y esta otra.
Después de entrenar la red me dí cuenta que me daba resultados muy sesgados, y ahí supe que nunca hice un balanceo de pesos de las clases debido a que no tengo el mismo número de imagenes para cada tipo de clase. Para solucionarlo use el método de cálculo de pesos de clases de scikit-learn y volví a entrenar la red y tuve resultados aun sesgados pero más aceptables.
-
Hacer transfer learning con una red ya preentrenada y que predijera en el ambito de mi problema. Para esto tome las redes vgg16 y vgg19 que tiene Keras ya incluidas y con el conjunto de imagenes de entrenamiento de imagenet. Lo probé así nomás y claramente me daba resultados sin mucho sentido pues la red no tenía incluidas imagenes de anime en su entrenamiento ni tampoco en la capa de salida así que cuando intentaba predecir imagenes que sabía que eran de anime, obtenía clases completamente diferentes. Aunque claro, esto era inevitable por el objetivo de mi red, las salidas de las vgg y el conjunto de entrenamiento de imagenet. Después quité las últimas capas de las redes vgg y agregé al tope las últimas de la red original y lo entrené. Las predicciones fueron terribles ya que estaba completamente sesgado a una clase y siempre con 100% de seguridad (aunque obviamente la imagen no pertenecía a esa clase). Fue entonces cuando, después de investigar porque sucedía, intenté hacer no entrenables todas las capas convolucionales y ya obtenía resultados mucho mejores.
-
Al entrenar las redes vgg, mi sistema se ralentizaba considerablemente. Al investigar esto, encontré que es debido a que mi GPU no tiene suficiente VRAM y partes del modelo se tienen que guardar en la RAM principal. El único arreglo que esto tiene es reducir el tamaño del modelo o comprar una tarjeta con más VRAM. Ninguna de las opciones suena bien para mi así que solo tuve que aguantarme.
-
La página web. Encontré una serie de video tutoriales de como hacer una aplicación en flask que usando un modelo de keras el cual prácticamente copié y funcionaba para un sólo ejemplo. El problema es que para que funcionara para multiples imagenes tuve que aplicar un cambio en el código por un error que parece tener la versión de tensorflow que usaba. Para arreglar ese error tuve que limpiar la sesion de keras y volver a cargar el modelo. Esto es poco óptimo pero al menos funciona.
-
Un problema que sigo sin poder solucionar es poder guardar la página con el modelo que predice en heroku. Si he podido correr la aplicación en flask localmente pero no en heroku.
Resultados encontrados
Después de toda la travesía, termine con 3 modelos. Un modelo igual al modelo del proyecto original, un modelo basado en el vgg16 y otro basado en el vgg19 para poder comparar los resultados. Además de esto, veré como se desempeña la red del proyecto original con un conjunto de prueba (conjunto con el cual calificare a todas, con unas 2000 imágenes que son de anime y otras 2000 que no lo son).
-
Original
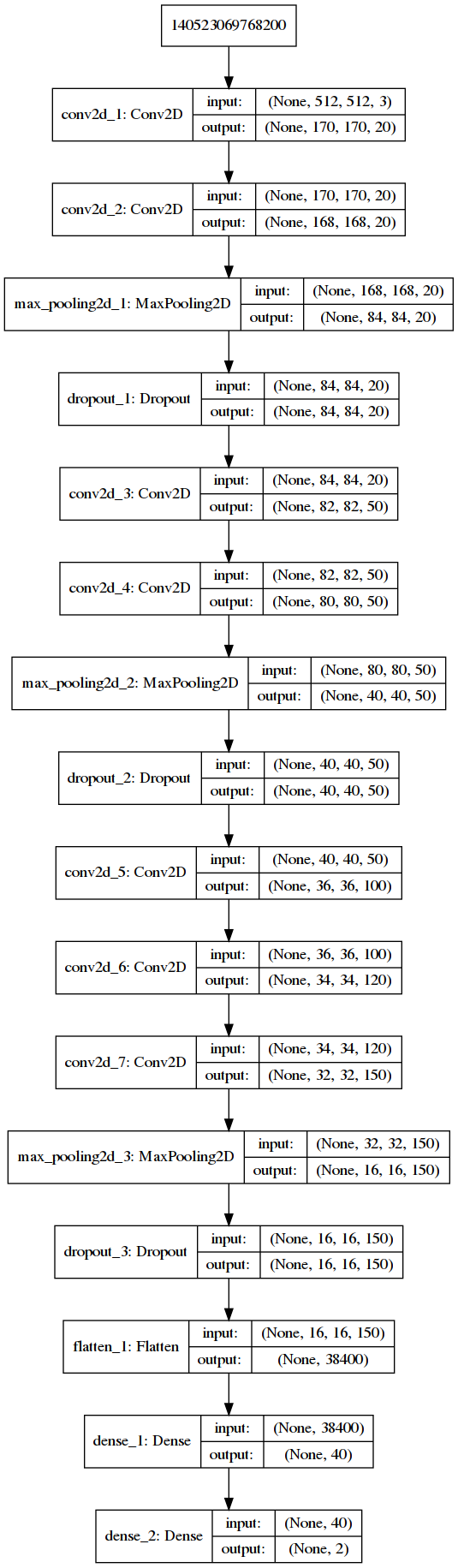
Visualmente el modelo se ve:
La matriz de confusión de la predicción al conjunto de prueba:
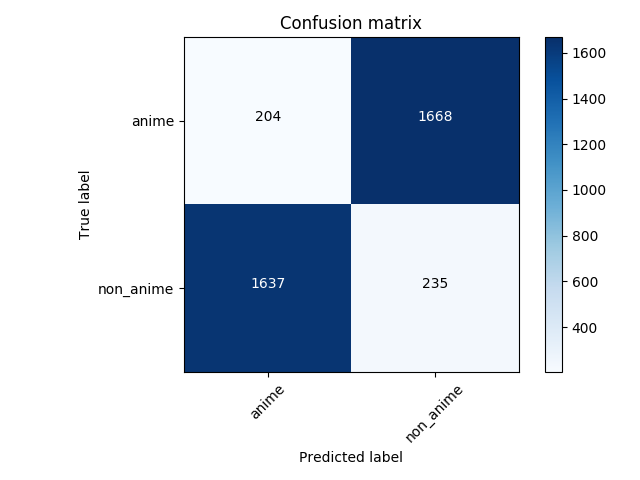
El proyecto original tomaba las clases al reves y por eso se ve tan mal pero si invertimos las predicciones, tiene un 88% de aciertos y es uniforme para ambas clases.
Ejemplo de clasificación incorrecta y de clasificación correcta:


-
Base
Visualmente el modelo se ve:
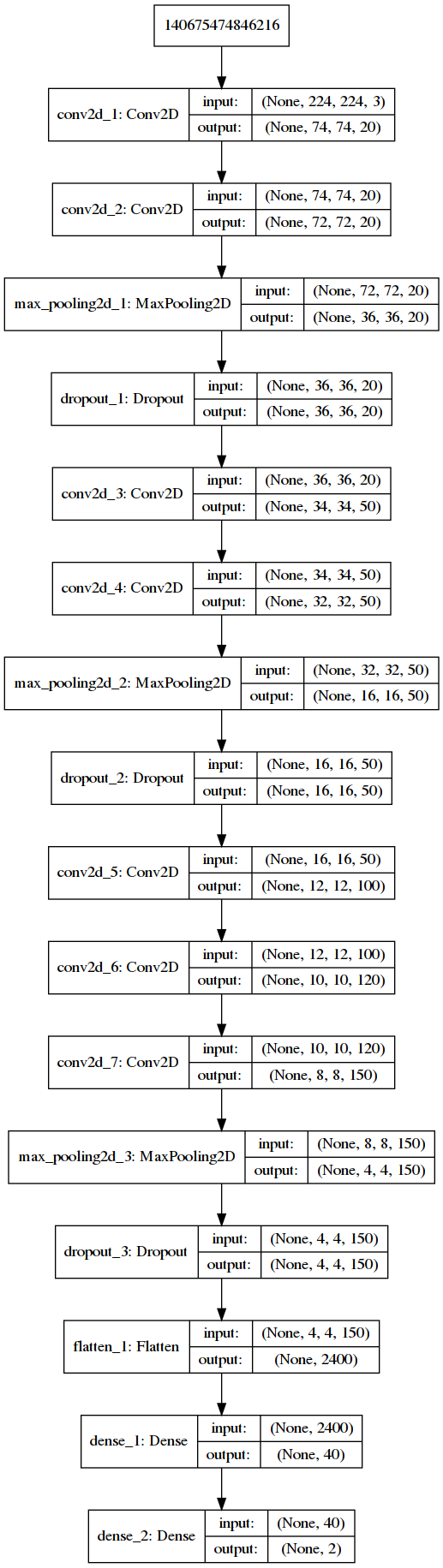
La matriz de confusión de la predicción al conjunto de prueba:
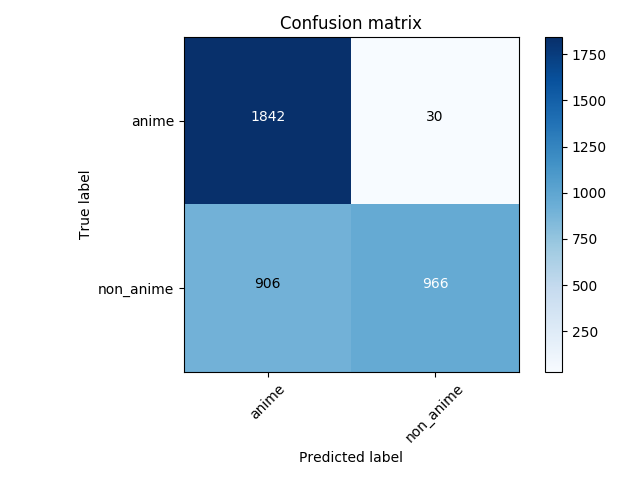
75% de precisión en general pero cuando se trata de imágenes de no anime practicamente no es mejor que el azar.
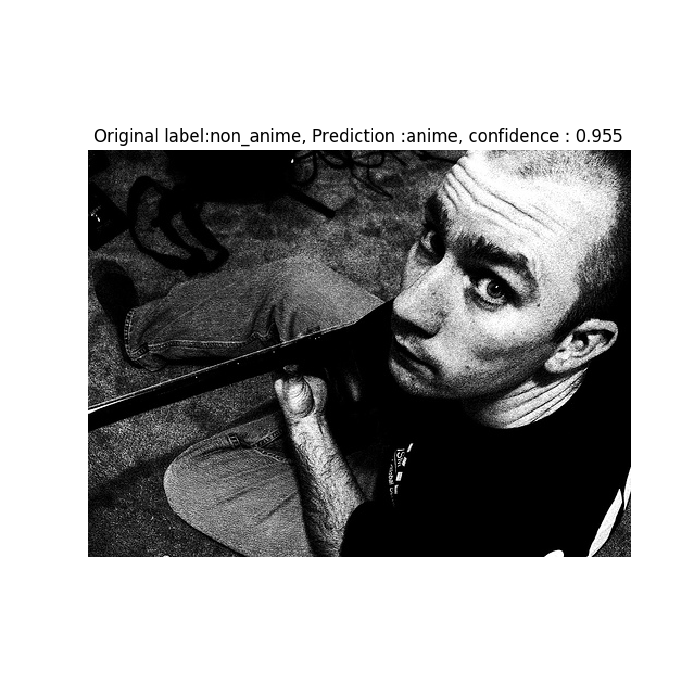
Ejemplo de clasificación incorrecta:
-
vgg16
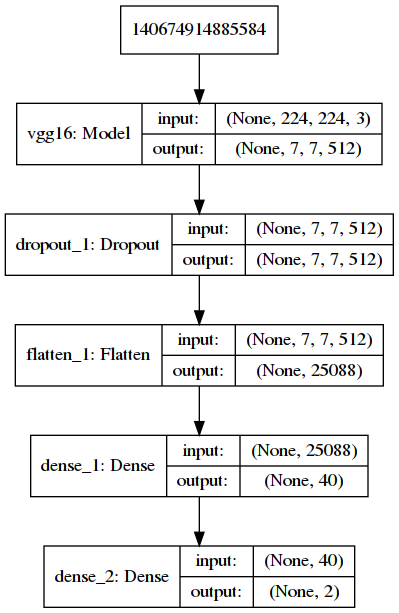
Visualmente el modelo se ve:
La matriz de confusión de la predicción al conjunto de prueba:
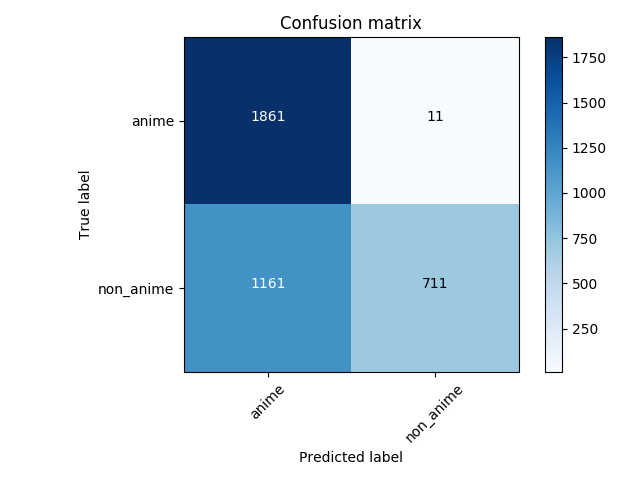
68% de precisión. En el caso de no anime, es incluso peor que el azar.
Ejemplo de clasificación incorrecta:

-
vgg19
Visualmente el modelo se ve:
La matriz de confusión de la predicción al conjunto de prueba:
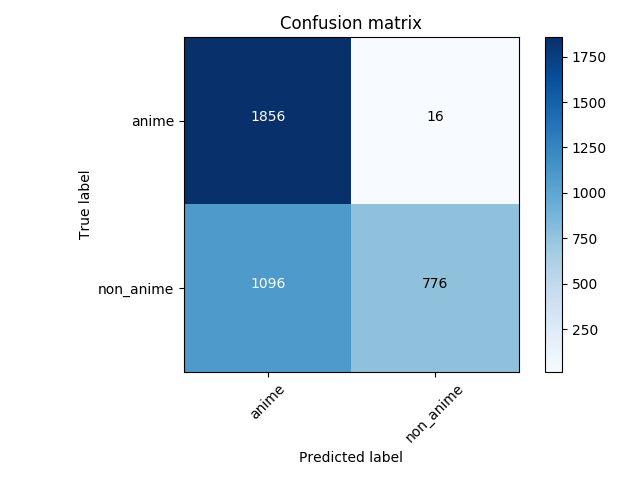
79% de precisión. En el caso de no anime, es incluso peor que el azar.
Ejemplo de clasificación incorrecta:

Esto no se ve tan bien
Estos resultados obtenidos no son tremendamente malos pero tampoco son brillantes. Considerando que solo se trata de un clasificador binario, esto debería ser mucho mejor.
Entonces, ¿Qué es lo que podría hacer?
Mejorando los resultados
Cuando terminé de etrenar los primeros modelos me puse a pensar en como podría mejorarlos y si hice las cosas bien. También está a considerarse el desbalance en el número de imágenes de anime y no anime, por lo busque formas de mejorar los modelos y también de disminuir el desbalance de las imágenes. Aún más, hay quienes dicen que una red neuronal es tan buena como los datos que se tengan, así que aumentar el número de datos debería aumentar positivamente los resultados de las redes.
Creo que encontre formas de mejorarlos.
Encontrando más datos
Para combatir el desbalance de clases en mis imágenes, lo que decidí fue conseguir más de la clase que más me faltaba: no anime; además que las imagenes que tengo de no anime, debido al sitio de donde las saqué, en algunos casos son repetidas con cambios muy leves, principalmente cortadas para que tengan diferente tamaño, lo cual empeora la habilidad de predicción del modelo.
Busqué conjuntos de imagenes grandes y variados de donde pueda sacar muchas imágenes, al menos suficientes para igualar el número de ejemplares de no anime que de anime, y después de mucha busqueda me econtré con una base de datos del sitio flickr la cual se me hizo suficientemente buena para mis necesidades.
Ya con esto obtuve suficientes datos y debería mejorar los resultados de mis redes.
Cambiando normalización de los modelos
La principal normalización que tenían los modelos era que aumentaba mis datos, rotaba, invertía ejes o movía ligeramente las imágenes a los lados, pero con el aumento de datos que tengo creo que ya no será necesario. En su lugar me encontré con una recomendación: no usar dropout y usar normalización de batch. Resulto una leída interesante y mientras seguía investigando, me encontraba más opiniones a favor del uso de normalización de batches y que hay quienes dicen que incluso se puede usar junto con dropout y pueden dar resultados mejores. Además también encontré que el dropout por default es de 0.5 ya que da la mayor varianza. En las redes que he entrenado hasta el momento han tenido dropout de 0.2 ya que la red original usaba ese número y no pensé en probar cambiandolo.
Y en el caso particular del modelo base, encontré que aumentar el número de capas densas y el número de neuronas mejoraba los resultados de predicción. Estoy completamente consciente que esto puede resultar en un fuerte sobreaprendizaje por el gran aumento en el número de parametros, pero encontré mejores resultados de esa manera (lastimosamente no tengo los resultados de la red entrenada con pocas neuronas).
Nuevos resultados encontrados
Aplicando las mejoras anteriores, el resultado del entrenamiento de los modelos, con el base y vgg16 entrenado 100 epochs y el vgg19 con unos 50 epochs. Además que únicamente el modelo base tiene removido el aumento de datos y los vgg todavía fueron entrenados con aumento de datos.
Los resultados fueron:
-
Base
Visualmente el modelo se ve:

La matriz de confusión de la predicción al conjunto de prueba:
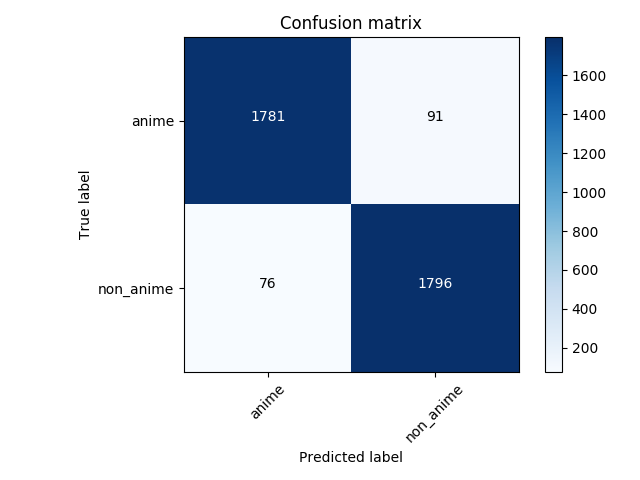
95% de precisión.
Ejemplo de clasificación incorrecta y de clasificación correcta:


-
vgg16
Visualmente el modelo se ve:
La matriz de confusión de la predicción al conjunto de prueba:
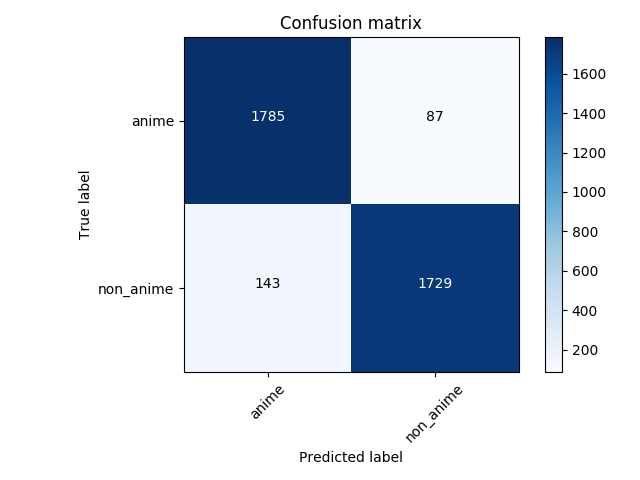
94% de precisión.
Ejemplo de clasificación incorrecta y de clasificación correcta:

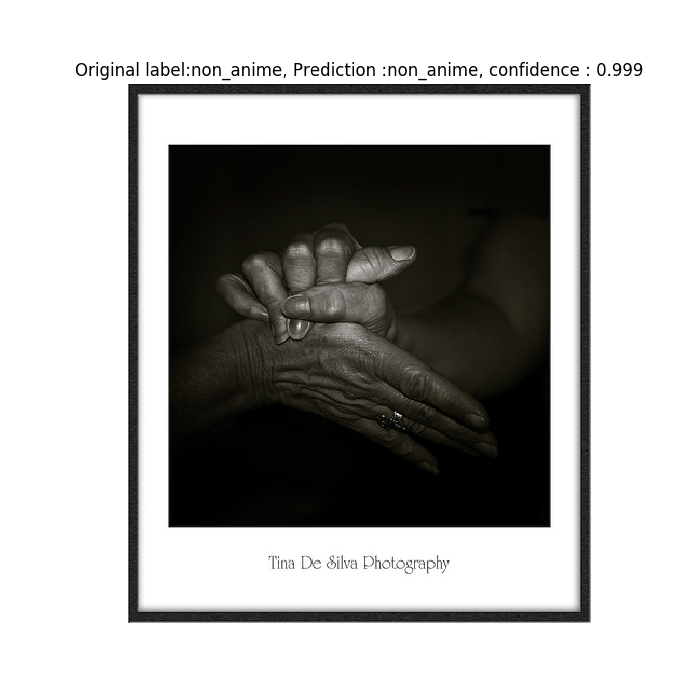
-
vgg19
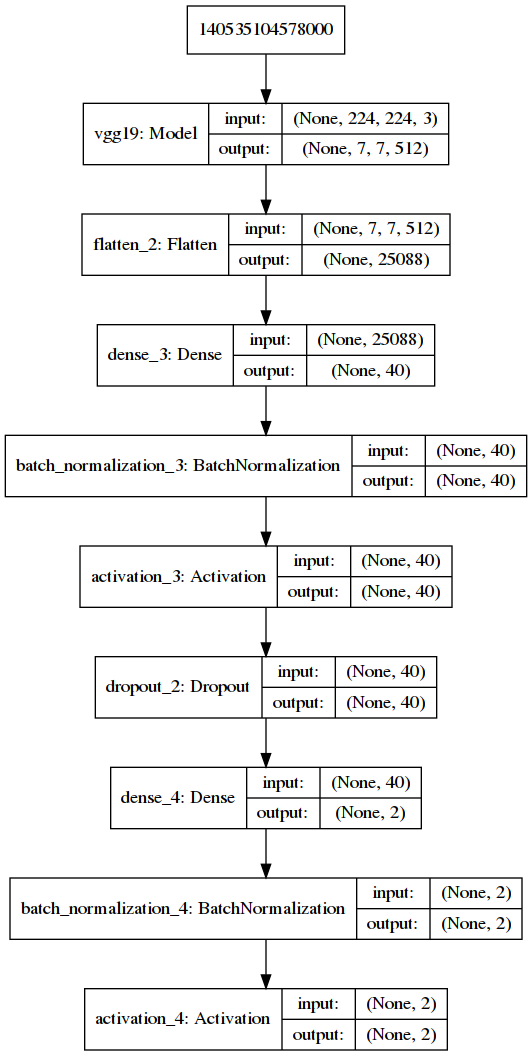
Visualmente el modelo se ve:
La matriz de confusión de la predicción al conjunto de prueba:
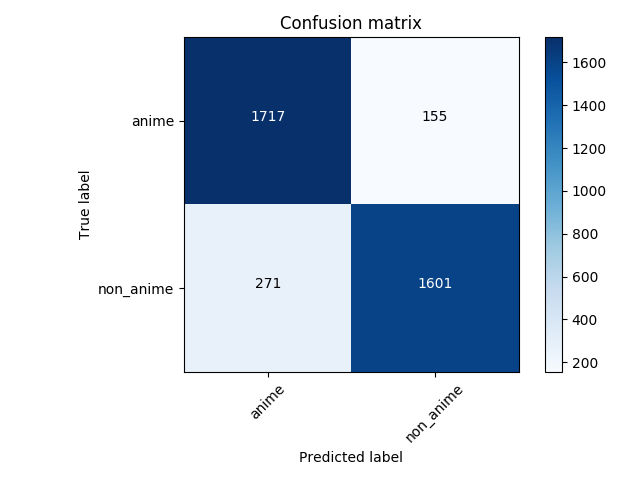
88% de precisión.
Ejemplo de clasificación incorrecta y de clasificación correcta:


Clasificador de imágenes individuales
Todas las imágenes que mostre como ejemplos anteriormente fueron imagenes que venían de la evaluación masiva del conjunto de prueba, pero para clasificar una imagen individual con mayor facilidad está la página web (la cual no pude subir en heroku para dejarla disponible a quien quiera utilizarla).
La versión actual de la página web es prácticamente una copia peor de la página web del modelo original (esta). De hecho las imágenes del inicio de la entrada del blog fueron tomadas usando ese clasificador con el modelo mejora de vgg16.
Conclusiones
De los objetivos que me plantié, los resultados fueron:
-
Encontrar datos de entrenamiento por mi mismo para mis modelos Logré este objetivo con relativa facilidad gracias a la base de datos de kaggle de safebooru y a flickr.
-
Reusar modelos ya entrenados para disminuir el esfuerzo computacional que mi red tendrá que aplicar. Los modelos vgg16 y vgg19 cumplen este objetivo, pues en menos epochs lograron resultados equivalentes a la red base con más epochs, pero parecían quedarse atascados con la misma perdida y precisión, lo cual permitía al modelo base alcanzarlos con más epochs. Aunque es de notarse que al entrenar las redes vgg16 y vgg19, no solo necesite de la VRAM de mi GPU sino también del RAM de mi computadora, ralentizandola.
-
Comparar los resultados obtenidos con los de la red del proyecto original.
Ciertamente fue logrado. Y comparando los resultados, puedo decir que para mis datos de prueba mis modelos son mejores porque tienen mayor precisión.
-
Crear una aplicación web similar a la del proyecto original pero en heroku. Lastimosamente no lo pude lograr. No estoy seguro de las razones por las cuales sucede.
En cuanto a los resultados obtenidos, los modelos entrenados con más datos son mucho mejores que los primeros modelos. De hecho, estos si son mejores o iguales que el modelo del autor original, con lo que me quedo bastante satisfecho.
Al final puedo decir que fue una buena experiencia y me hizo interesarme más aún más en el tema de redes neuronales y estoy buscando proyectos que hacer, no necesariamente para la clase, pues resulta divertido y creo que aprendí bastante gracias a toda la busqueda de información que hice. El único problema que podría tener es que quiza sea lento el entrenamiento de las redes por el equipo de computo con el que cuento yo y la universidad de Sonora.