Generación de música con LSTM
Breve introducción
Buscando proyectos sobre aplicaciones de redes neuronales recurrentes, los principales temas que veía eran sobre generación de texto o generación de música. Al elegir entre ellos decidí centrarme en la generación de música y buscar proyectos relacionados a esto. En mi busqueda me encontré con esta entrada de blog en la que genera música de piano usando una red neuronal LSTM con Keras y entrenada con música de final fantasy.
Ahora, una intruducción hyper superficial sobre lo que son las redes neuronales recurrentes y LSTMs:
Redes neuronales recurrentes
Una red neuronal recurrente es una red que tiene memoria interna. Gracias a esta memoria les es posible ser más precisa en predicciones sobre que es lo siguiente que debería suceder. Ya que estas redes pueden entender contexto de la información, son el tipo de red ideal cuando se está tratando con datos secuenciales: lenguaje hablado y escrito, música, películas, el clima, etc., lo cual tiene sentido cuando piensas que por ejemplo cuando hablas lo siguiente que vas a decir depende de el flujo de la conversación hasta el momento, o que el clima de mañana depende en parte del clima de hoy.
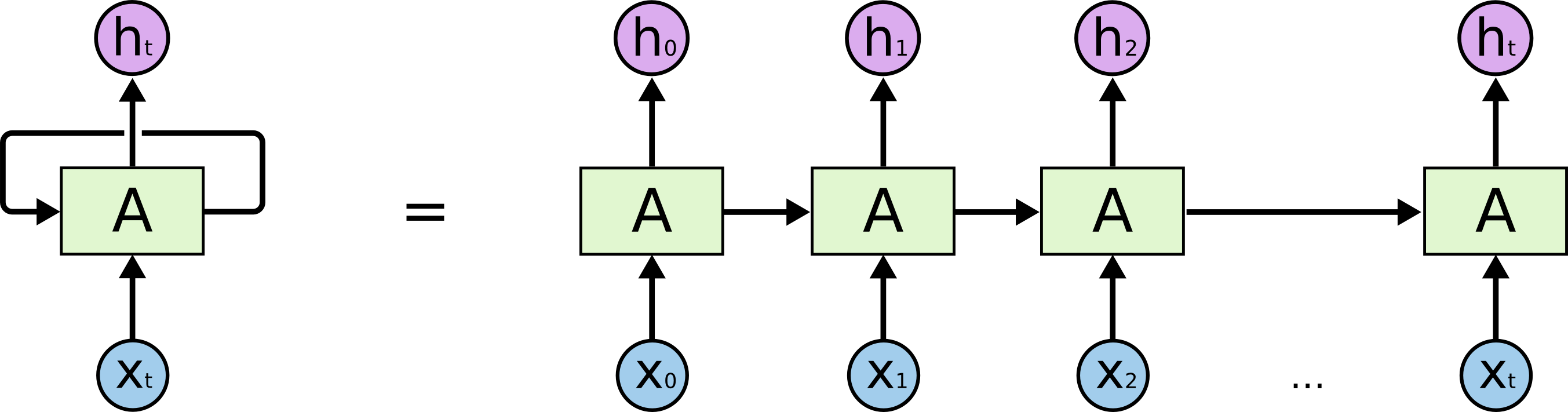
Algo curioso de estas redes neuronales es que el concepto no es nuevo. Desde 1980 parecen existir pero hasta hace pocos años se ha tenido el suficiente poder de computo para hacerlas andar y que den resultados.
Long short-term memory (LSTM)
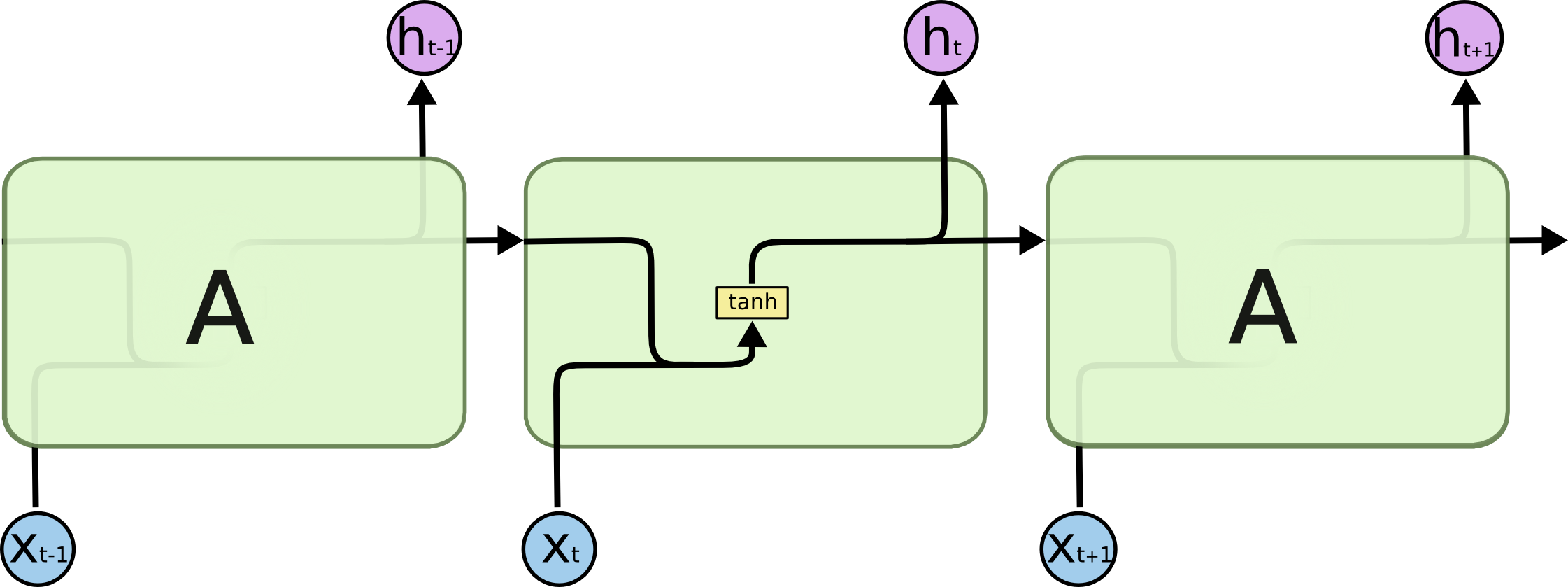
Las redes LSTM son una variante de red neuronal recurrente. Estas redes surgieron principalmente para solventar un problema de dependencia de las redes recurrentes. Cuando el contexto necesario para predecir es de relativamente corto plazo, las redes recurrentes no tienen problemas, pero cuando se necesita de información que se remonte a entradas mucho más anteriores, se les dificulta predecir correctamente. No es que sea imposible, es técnicamente cierto que bajo ciertos pesos es posible que la red no tenga problemas de ese tipo, pero en la práctica esto no sucede. Aquí es donde entran las redes LSTM a salvar el día ya que fueron diseñadas para combatir justo ese problema.
Así como las redes recurrentes, las redes LSTM no son especialmenten nuevas. Existen desde más o menos 1990 pero han tenido que esperar hasta el poder de computo actual para poder mostrar buenos resultados.
music21
Lo que hace el proyecto es leer la música en formato MIDI usando music21 para extraer las notas de lo archivos MIDI con los que se quiere aprender para generar música similar.
Música utilizada
El proyecto original utiliza música de Final Fantasy para entrenar su red. Personalmente no soy un fanático de Final Fantasy ni he tenido la oportunidad de jugar a algún juego de ellos por lo que busqué opciones de distinta música que podría utilizar. En mi busqueda me encontre con el sitio VGMusic que contiene música de muchos videojuegos en formato MIDI, incluso tienen una sección dedicada a únicamente música MIDI de piano. En esa misma sección había un número relativamente grande de música de The Legend of Zelda, la cual es una serie de videojuegos que si he tenido el placer de jugar así que me decidí utilizar la música de Zelda que la página provee. Su selección está incompleta pero tiene algunas canciones de juegos como The Legend of Zelda: Ocarina of Time, The legend of Zelda: Majora’s Mask, The Legend of Zelda: The Wind Waker y The Legend of Zelda Twilight Princess, ya que cada juego tiene un tono variado pienso que el resultado puede ser interesante.
Modelo
El modelo de la red es muy similar al modelo original, los únicos cambios que hice fue aumentar el número de neuronas de las capas de LSTM, aumentar el dropout entre las capas y cambiar el optimizador de rmsprop a Adam
def create_network(network_input, n_vocab):
model = Sequential()
model.add(LSTM(
512,
input_shape=(network_input.shape[1], network_input.shape[2]),
return_sequences=True
))
model.add(Dropout(0.5))
model.add(LSTM(512, return_sequences=True))
model.add(Dropout(0.5))
model.add(LSTM(512))
model.add(Dense(256))
model.add(Dropout(0.5))
model.add(Dense(n_vocab))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
Además en cuanto al entrenamiento, cambié el número de batches de 64 a 32 y el número de epochs a 250.
Aparte del cambio al modelo, no hice algún otro cambio que merezca ser mencionado en el código que no fuese para facilitarme el entrenamiento.
Resultados
Para ver si ocurrian diferencias, entrene por separado el modelo desde 0 usando únicamente música de cada juego diferente y una última vez utilizando la música de todos los juegos.
Ocarina of Time
De Ocarina of Time obtuve 16 canciones para entrenar pero desafortunadamente perdí los pesos del modelo entrenado y solo tengo los resultados:



Majora’s Mask
De Majora’s Mask obtuve 9 canciones para entrenar y la menor pérdida obtenida fue en el epoch 106 con 0.0259 de pérdida.


The Wind Waker
De The Wind Waker obtuve 14 canciones para entrenar y la menor pérdida obtenida fue en el epoch 210 con 0.0105 de pérdida.




Twilight Princess
De The Wind Waker obtuve 10 canciones para entrenar y la menor pérdida obtenida fue en el epoch 220 con 0.0324 de pérdida.



Zelda
Finalmente, entrenando con todas las cancione de zelda que pude obtener, 49 en total, la menor pérdida obtenida fue en el epoch 234 con 0.0368 de pérdida.
Como es el resultado de todas las canciones juntas, corrí 3 veces la generación de música para ver que diferencias había cada vez que generaba.
Resultado 1



Resultado 2



Resultado 3



Conclusiones
El entrenamiento para cada tipo de juego fue solo una ocurrencia que tuve, pero creo que quedó bastante bien. En cada uno se puede identificar un estilo particular de los juegos, y creo que si los has jugado vas a poder notar que suenan similares. La única excepción es con la música de The Wind Waker ya que pienso que no suena nada bien y es difícil saber que se trata de música de ese juego. Quizá si hubise tenido más música de todos los juegos hubiese dado mejores resultados.
Mi intención era tomar todas las canciones y entrenar con todas, y el resultado fue interesante. Creo que las 3 veces que generé la música daba resultados aceptables, mostrando a veces los diferentes estilos de los juegos y cambiando de uno a otro. Especialmente el el segundo resultado mas o menos por el segundo 0:17 se puede notar que es la canción Midna’s Lament de Twilight Princess (video de YouTube con la canción para comparar). Me imagino que esto sucedio porque el modelo está algo sobreentrenado por la función de pérdida tan baja y que la red eligé la nota que mejor se acomode, así que toma práćticamente las mismas notas que las originales.
Los resultados están lejos de ser perfectos pero son cuando menos interesantes. Si pudiese retomar el proyecto después quisiera hacerlo con más música representativa de cada juego de The Legend of Zelda y probar con una red más compleja para ver si puede dar mejores resultados, pero para ello necesitaría un mejor equipo de computo ya que cada entrenamiento me tomaba al rededor de 2 días.
Agradecimientos
-Sigurður Skúli por su post de donde saqué el proyecto de generación de música usando redes LSTM. -A Christopher Olah por su post que creo que explica muy clara e intuitivamente que es una red LSTM. -Dr. Julio Waissman por su clase de redes neuronales.